pyControl data¶
pyControl versions ≥2.0 generate .tsv (tab separated value) data files, whose name is determined by the subject ID, start date and time, e.g. m1-2023-10-30-214942.tsv. For pyControl versions <2.0 see the Old data format section below.
.tsv files are a generic way of storing tabular data, which can be opened in text editors, spreadsheets, or tabular data viewers such as Tad, and imported into most programming languages (e.g. using pandas.read_csv in Python).
This is the contents of a data file generated by the button example task:
time type subtype content
0.000 info experiment_name run_task
0.000 info task_name example\button
0.000 info task_file_hash 581374133
0.000 info setup_id COM4
0.000 info framework_version 2.0rc1
0.000 info micropython_version 1.11
0.000 info subject_id test
0.000 info start_time 2023-10-04T16:36:56.647
0.000 variable run_start {"press_n": 0}
0.000 state LED_off
7.303 event input button_press
7.304 print task Press number 1
7.995 event input button_press
7.995 print task Press number 2
8.833 event input button_press
8.833 print task Press number 3
8.834 state LED_on
9.834 state LED_off
10.117 event input button_press
10.118 print task Press number 1
13.206 variable run_end {"press_n": 1}
13.206 info end_time 2023-10-04T16:37:09.980
which represents the following table:
| time | type | subtype | content |
|---|---|---|---|
| 0 | info | experiment_name | run_task |
| 0 | info | task_name | example\button |
| 0 | info | task_file_hash | 581374133 |
| 0 | info | setup_id | COM4 |
| 0 | info | framework_version | 2.0rc1 |
| 0 | info | micropython_version | 1.11 |
| 0 | info | subject_id | test |
| 0 | info | start_time | 2023-10-04T16:36:56.647 |
| 0 | variable | run_start | {"press_n": 0} |
| 0 | state | LED_off | |
| 7.303 | event | input | button_press |
| 7.304 | task | Press number 1 | |
| 7.995 | event | input | button_press |
| 7.995 | task | Press number 2 | |
| 8.833 | event | input | button_press |
| 8.833 | task | Press number 3 | |
| 8.834 | state | LED_on | |
| 9.834 | state | LED_off | |
| 10.117 | event | input | button_press |
| 10.118 | task | Press number 1 | |
| 13.206 | variable | run_end | {"press_n": 1} |
| 13.206 | info | end_time | 2023-10-04T16:37:09.980 |
The time column indicates the time, in seconds since the start of the session, that the row was generated.
The type column indicates what type of information the row contains, and can be either info, state, event, print, variable, warning or error.
The subtype and content columns contain data that depends on the row type:
-
inforows contain information about the session including subject, task and experiment names, session start and end date-times (in ISO 8601 format), and the pyControl and Micropython version numbers. -
eventrows are generated by framework events. Thecontentcolumn indicates the event name. Thesubtypecolumn indicates what triggered the event, and can be:input: events triggered by external inputstimer: events triggered by timersuser: events triggered by the user from the GUI Controls dialogapi: events triggered by the pyControl APIpublish: events triggered by the task using the publish_event functionsync: sync pulse events generated by anRsyncorFrame_loggerobject (see Synchronisation docs)
-
staterows are generated by state transitions, thecontentcolumn indicates the name of the state that was entered. -
printrows contain text output. Thecontentcolumn contains the printed text and thesubtypecolumn indicates what generated the print, and can be:task: print statements in the task fileuser: notes added to the log by the user from the Controls dialogapi: text printed by the API.
-
variablerows contain information about task variables. Thecontentcolumn contains the values of one or more task variables, as a JSON formatted string representing a dictionary of{variable_name: variable value}pairs. Thesubtypecolumn indicates what operation generated the variable row, and can be:get: variable was read using the GUI Controls dialoguser_set: variable was set using the GUI Controls dialogapi_set: variable was set by the APIprint: variable was output by the task using the print_variables functionrun_start: value of all task variables at the start of the sessionrun_end: value of all task variables at the end of the session
Analog data¶
Each analog input (or other source of analog data such as rotary encoders) generates a pair of .npy files, one of which contains the values of the analog data samples and the other the corresponding timestamps (in seconds since the start of the run). The .npy file format is used by NumPy to save arrays to disk, and can be loaded into Python with numpy.load. Most programming languages used for data analysis also support loading .npy files.
The file names are determined by the subject ID, start date time and analog input name, e.g. m001-2018-01-30-214942._analog1.data.npy and m1-2018-01-30-214942._analog1.time.npy for the data and timestamp files respectively.
While the session is running analog data is saved to temporary files, that are converted to .npy at the end of the session. In the event that a session is not stopped normally and the conversion to .npy does not occur, running the script analog_temp2npy.py in the tools folder will convert any temporary analog data files in the data folder to .npy.
Versioned task files¶
Task files used to generate data are also stored in the data folder, with a file hash appended to the task file name to uniquely identify the file version. The file hash of the task file used for each session is recorded in that session's data file so the exact task file version used to run each session can be identified. We encourage users to treat these versioned task files as part of the experiment's data, and to include them in data repositories to promote replicability of pyControl experiments.
Importing data¶
As pyControl data uses generic file formats (.tsv and .npy), it can be loaded into most programming languages using standard libraries. For example to load a pyControl session with analog data into Python you can do:
import pandas as pd
import numpy as np
session_df = pd.read_csv('path/to/session/tsv/file', sep='\t')
analog_signal = np.load('path/to/session/npy/file')
There is a data_import module in the tools folder which contains Python classes and functions for importing and representing pyControl data. This is in large part a hold-over from pyControl versions < 2.0 (see Old data format below) which used custom data formats and hence it was useful to have tools to simplify importing data. The data import code is designed to work with both old and new data formats, and as far as possible generates identical Python data structures for both file formats, with the exception of some information present in the new .tsv data files that was not available in the old .txt files.
The data import module implements two different approaches for representing pyControl data in Python. The first uses custom Python classes to represent pyControl data; a Session class represents data from a single session, and an Experiment class represents data from an experiment consisting of multiple sessions and subjects. The second uses pandas dataframes to represent data, with a session_dataframe function to generates a dataframe from a single session's data file, and an experiment_dataframe function to generate a dataframe containing data from multiple sessions and subjects.
The data import module has dependencies:
- Python 3
- NumPy
- pandas
Session¶
The Session class is used to import a pyControl data file and represent it as a Python object.
Example usage:
import data_import as di # Import the data import module.
# Instantiate session object from data file.
session = di.Session('path//to//session//file')
session.events # List of state entries and events in order they occured.
# Each item is a namedtuple with fields 'time' & 'name', such that
# you can get the name and time of event/state entry x with x.name
# and x.time respectively.
session.times # Dictionary with keys that are the names of the framework events
# and states, and values which are NumPy arrays of the times (in
# milliseconds since the start of the framework run) at which
# the event/state entry occured.
session.prints # List of all the lines output by print statements during the
# framework run, each as a namedtuple with fields 'time' and 'string'
Class reference
class Session(file_path, time_unit="second")
Arguments:
file_path Path of the pyControl data file to import.
time_unit Whether times are represented units of "second" or "ms".
Attributes:
Session.file_name Name of data file.
Session.experiment_name Name of experiment.
Session.task_name Name of the pyControl task used to generate the file.
Session.subject_id ID of subject.
Session.datetime The date and time that the session started stored as a datetime object.
Session.datetime_string The date and time that the session started stored as a string of format 'YYYY-MM-DD HH:MM:SS'
Session.events List of state entries and events in order they occurred. Each item is a namedtuple with fields 'time' & 'name', such that you can get the name and time of event/state entry x with x.name and x.time respectively.
Session.times Dictionary with keys that are the names of the framework events and states and values which are NumPy arrays of the times at which the event/state entry occurred.
Session.prints List of all the lines output by print statements during the framework run. Each item is a named tuple with fields 'name', 'subtype', and 'string', such that you can get the time and printed string of entry x with x.time and x.string respectively.
Session.variables_df Dataframe containing the values of task variables. For .txt data files only variables output with the print_variables function are included.
Experiment¶
The Experiment class is used to import all data files from a given experiment (stored in a single folder) and represent the experiment as a Python object. The experiment class has a method get_sessions which can be used to flexibly select sessions from specific subjects and times. Individual sessions in the Experiment are represented as instances of the Session object detailed above.
Example usage:
import data_import as di # Import the data import module.
# Instantiate experiment object from data folder.
experiment = di.Experiment('path//to//experiment//folder')
# Save sessions as a .pkl file to speed up subsequent loading of experiment.
experiment.save()
# Return session number 1 for all subjects.
experiment.get_sessions(subject_IDs='all', when=1)
# Return session numbered 1,3 or 5 for all subjects.
experiment.get_sessions(subject_IDs='all', when=[1,3,5])
# Return sessions from specified subjects and date.
experiment.get_sessions(subject_IDs=[12,13], when='2017-06-23')
Class reference
class Experiment(folder_path, time_unit="second")
Arguments:
folder_path Path of the pyControl data folder to import.
time_unit Whether times are represented units of "second" or "ms".
Attributes:
Experiment.folder_name Name of the experiment folder.
Experiment.path Path of the experiment folder
Experiment.sessions List of all sessions in experiment.
Experiment.subject_IDs List of all subject IDs
Experiment.n_subjects Number of subjects.
Methods:
Experiment.save()
Save all sessions as .pkl file. Speeds up subsequent instantiation of experiment as sessions do not need to be created from data files.
Experiment.get_sessions(subject_IDs='all', when='all')
Returns a list of sessions which match specified subject IDs and time.
subject_IDs argument can be a list of subject IDs or 'all' to select sessions from all subjects.
when argument determines session numbers or dates to select, see examples below:
when = 'all' # All sessions
when = 1 # Sessions numbered 1
when = [3,5,8] # Session numbered 3,5 & 8
when = [...,10] # Sessions numbered <= 10
when = [5,...] # Sessions numbered >= 5
when = [5,...,10] # Sessions numbered 5 <= n <= 10
when = '2017-07-07' # Select sessions from date '2017-07-07'
when = ['2017-07-07','2017-07-08'] # Select specified list of dates
when = [...,'2017-07-07'] # Select session with date <= '2017-07-07'
when = ['2017-07-01',...,'2017-07-07'] # Select session with '2017-07-01' <= date <= '2017-07-07'.
Session dataframe¶
The session_dataframe function can be used to create a pandas dataframe from a pyControl .tsv or .txt data file. The dataframe has the same columns as the .tsv data files; time, type, subtype and content (see above). The only differences between the dataframe generated by session_dataframe and by importing a .tsv data file with Pandas.read_csv() are:
-
The addition of a
durationcolumn indicating the duration of states, and optionally of events specified as coming in pairs corresponding to the start and end of an action (e.g. pressing and releasing a lever). When a start-event end-event pair occurs in the data, only the start_event generates a row in the dataframe, with the end event used to compute the duration. -
Conversion of the
contentofvariablerows from JSON formatted strings to Python dicts{variable_name:variable_value}
Example usage:
import data_import as di # Import the data import module.
# Create Pandas dataframe from session data file.
df = di.session_dataframe('path//to//session//file')
# Create dataframe specifying that lick on/off events and lever press/release events are paired.
df = di.session_dataframe('path//to//session//file', paired_events={'lick_on':'lick_off', 'lever_press':'lever_release'})
# Create dataframe specifying that all events that end in '_out' (e.g. 'left_poke_out') are pair-end events.
df = di.session_dataframe('path//to//session//file', pair_end_suffix='_out')
Function reference
session_dataframe(file_path, paired_events={}, pair_end_suffix=None)
Arguments:
file_path Path of the pyControl data file to import.
paired_events Dictionary of {'start_event': 'end_event'} that indicates events that come in pairs corresponding to the start and end of an action.
pair_end_suffix String indicating that all events that end with this suffix are the end event of event pairs corresponding to the start and end of an action. The corresponding start event name is found by matching the stem of the event name. For example if the task had events 'left_poke', 'right_poke_in', 'left_poke_out' and 'right_poke_out', specifying pair_end_suffix='_out' would be equivalent to explicitly specifying paired_events={'left_poke':'left_poke_out','right_poke_in':'right_poke_out'}
Experiment dataframe¶
The experiment_dataframe function can be used to create a pandas dataframe from a folder containing pyControl data files from multiple sessions and subjects. The experiment dataframe has the same columns as the session dataframe ('type', 'name', 'time', 'duration', 'value'), plus additional columns specifying the subject_ID, start data and time etc., generated from the info lines in the pyControl data file. Each row of the dataframe corresponds to a single state entry, event or print line from a single session.
As with the session_dataframe function, events can optionally be specified as coming in pairs corresponding to the start and end of an action, e.g. entering and exiting a nosepoke. When a start-event end-event pair occurs in the data, only the start_event generates a row in the dataframe, with the end event used to compute the duration.
Example usage:
import data_import as di # Import the data import module.
# Create Pandas dataframe from an experiment data folder.
df = di.experiment_dataframe('path//to//experiment//folder')
# Create dataframe specifying that lick on/off events and lever press/release events are paired.
df = di.experiment_dataframe('path//to//experiment//folder', paired_events={'lick_on':'lick_off', 'lever_press':'lever_release'})
# Create dataframe specifying that all events that end in '_out' (e.g. 'left_poke_out') are pair-end events.
df = di.experiment_dataframe('path//to//experiment//folder', pair_end_suffix='_out')
Function reference
experiment_dataframe(folder_path, paired_events={}, pair_end_suffix=None)
Arguments:
folder_path Path of the experiment folder containing pyControl data files to import.
paired_events Dictionary of {'start_event': 'end_event'} that indicates events that come in pairs corresponding to the start and end of an action.
pair_end_suffix String indicating that all events that end with this suffix are the end event of event pairs corresponding to the start and end of an action. The corresponding start event name is found by matching the stem of the event name. For example if the task had events 'left_poke', 'right_poke_in', 'left_poke_out' and 'right_poke_out', specifying pair_end_suffix='_out' would be equivalent to explicitly specifying paired_events={'left_poke':'left_poke_out','right_poke_in':'right_poke_out'}
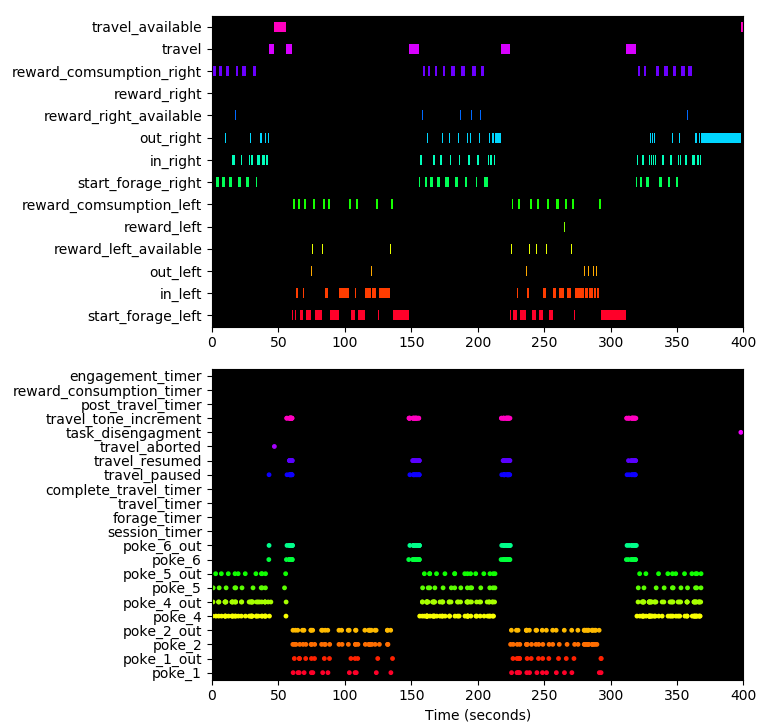
Visualising data¶
The session_plot module in the tools folder contains functions for visualising pyControl data offline.
The session plot module has dependencies:
- Python 3
- NumPy
- matplotlib
Example usage:
import session_plot as sp # Import the session plot module.
sp.session_plot('path//to//session//file') # Plot a session.
sp.session_plot('path//to//session//file', fig_no=2) # Plot a session in figure 2.
sp.play_session('path//to//session//file') # Scrolling animation of session.
sp.play_session('path//to//session//file', start_time=30) # Scrolling animation of session starting at 30 seconds.
Session plot
Old data format¶
pyControl versions <2.0 used .txt and .pca files for state/event and analog data respectively, rather than the .tsv and .npy files now used. We recommend updating pyControl to use the new format as it has several advantages:
-
The new generic file formats can be easily imported into most programming languages without custom code.
-
The
.tsvfiles contain information not present in the.txtfiles including:- The value of all task variables at the start and end of the session.
- The pyControl and computer clock timestamps when the session ended.
- Additional information about what operation generated events, print lines and variable values.
- The
.tsvfiles are human-readable as they use state and event names rather than numerical IDs.
If you use the data_import module in Python for loading your data for analysis, then changing to the new data format should be straightforward as the current version of this module supports both old and new formats.
State and event data¶
Log files generated by pyControl version <2.0 are text files whose name is determined by the subject ID, start date and time, e.g. m001-2018-01-30-214942.txt
An example data file might read:
I Experiment name : example_experiment
I Task name : button
I Task file hash : 289826412
I Subject ID : m001
I Start date : 2018/01/30 21:49:42
S {"LED_on": 1, "LED_off": 2}
E {"button_press": 3}
D 0 2
D 8976 3
D 8976 1
P 8976 This is the output of a print statement
D 10162 3
V 10231 variable_name variable_value
D 10423 2
Lines beginning I contain information about the session including subject, task and experiment names, start date and time.
The single line beginning S is a JSON object (also a Python dict) containing the state names and corresponding IDs.
The single line beginning E is a JSON object (also a Python dict) containing the event names and corresponding IDs.
Lines beginning D are data lines with format D timestamp ID where timestamp is the time in milliseconds since the start of the framework run and ID is a state ID (indicating a state transition) or an event ID (indicating an event occurred).
Lines beginning P are the output of print statements with format P timestamp printed_output.
Lines beginning V indicate the value of a task variable along with a timestamp. These lines are generated whenever a variable is either set or read from the board by the GUI. Variables set prior to the task starting are given a timestamp of 0, and the value of summary variables printed at the end of the run are given a timestamp of -1.
Lines beginning ! indicate that an error occurred during the framework run and contain the error message.
Analog data¶
pyControl version <2.0 analog data files ('.pca' file extension) are binary data files created by analog inputs and other source of analog data such as rotary encoders. They consist of alternating timestamps and data samples, both saved as 4 byte little endian signed integers. The function load_analog_data in the data_import module (see below) loads a pyControl analog data file into Python, returning a NumPy array whose first column is timestamps and second column data samples
analog_data_array = load_analog_data('path//to//analog_data_file.pca')